


Next: psb_cdins Communication
Up: Data management routines
Previous: Data management routines
Contents
call psb_cdall(icontxt, desc_a, info,mg=mg,parts=parts)
call psb_cdall(icontxt, desc_a, info,vg=vg,flag=flag)
call psb_cdall(icontxt, desc_a, info,vl=vl,nl=nl,globalcheck=.true.)
call psb_cdall(icontxt, desc_a, info,nl=nl)
call psb_cdall(icontxt, desc_a, info,mg=mg,repl=.true.)
This subroutine initializes the communication descriptor associated
with an index space. One of the optional arguments
parts, vg, vl, nl or repl
must be specified, thereby choosing
the specific initialization strategy.
- On Entry
-
- Type:
- Synchronous.
- icontxt
- the communication context.
Scope:global.
Type:required.
Intent: in.
Specified as: an integer value.
- vg
- Data allocation: each index
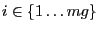 is allocated
to process
is allocated
to process 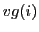 .
.
Scope:global.
Type:optional.
Intent: in.
Specified as: an integer array.
- flag
- Specifies whether entries in
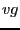 are zero- or one-based.
are zero- or one-based.
Scope:global.
Type:optional.
Intent: in.
Specified as: an integer value 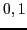 , default
, default 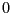 .
.
- mg
- the (global) number of rows of the problem.
Scope:global.
Type:optional.
Intent: in.
Specified as: an integer value. It is required if parts or
repl is specified, it is optional if vg is specified.
- parts
- the subroutine that defines the partitioning scheme.
Scope:global.
Type:required.
Specified as: a subroutine.
- vl
- Data allocation: the set of global indices belonging to the
calling process.
Scope:local.
Type:optional.
Intent: in.
Specified as: an integer array.
- nl
- Data allocation: in a generalized block-row distribution the
number of indices belonging to the current process.
Scope:local.
Type:optional.
Intent: in.
Specified as: an integer value. May be specified together with
vl.
- repl
- Data allocation: build a replicated index space (i.e. all
processes own all indices).
Scope:global.
Type:optional.
Intent: in.
Specified as: the logical value .true.
- globalcheck
- Data allocation: do global checks on the local
index lists
vl
Scope:global.
Type:optional.
Intent: in.
Specified as: a logical value, default: .true.
- On Return
-
- desc_a
- the communication descriptor.
Scope:local.
Type:required.
Intent: out.
Specified as: a structured data of type descdatapsb_desc_type.
- info
- Error code.
Scope: local
Type: required
Intent: out.
An integer value; 0 means no error has been detected.
Notes
- One of the optional arguments
parts, vg,
vl, nl or repl must be specified, thereby choosing the
initialization strategy as follows:
- parts
- In this case we have a subroutine specifying the mapping
between global indices and process/local index pairs. If this
optional argument is specified, then it is mandatory to
specify the argument
mg as well.
The subroutine must conform to the following interface:
interface
subroutine psb_parts(glob_index,mg,np,pv,nv)
integer, intent (in) :: glob_index,np,mg
integer, intent (out) :: nv, pv(*)
end subroutine psb_parts
end interface
The input arguments are:
- glob_index
- The global index to be mapped;
- np
- The number of processes in the mapping;
- mg
- The total number of global rows in the mapping;
The output arguments are:
- nv
- The number of entries in
pv;
- pv
- A vector containing the indices of the processes to
which the global index should be assigend; each entry must satisfy
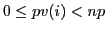 ; if
; if 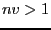 we have an index assigned to multiple
processes, i.e. we have an overlap among the subdomains.
we have an index assigned to multiple
processes, i.e. we have an overlap among the subdomains.
- vg
- In this case the association between an index and a process
is specified via an integer vector; the size of the index space is
equal to the size of
vg, and each index 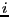 is assigned to
the process . The vector
is assigned to
the process . The vector vg must be identical on all
calling processes; its entries may have the ranges 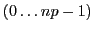 or
or 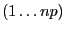 according to the value of
according to the value of flag. Optionally,
the user may specify mg, in
which case the portion vg(1:mg) is used.
- vl
- In this case we are specifying the list of indices assigned
to the current process; thus, the global problem size
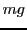 is given by
the range of the aggregate of the individual vectors
is given by
the range of the aggregate of the individual vectors vl specified
in the calling processes. If globalcheck=.true.
the subroutine will check how many times each entry in the global
index space 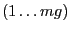 is specified in the input lists
is specified in the input lists
vl, thus allowing for the presence of overlap in the input,
and checking for ``orphan'' indices.
If globalcheck=.false., the subroutine will not check for
overlap, and may be substantially faster, but
the user is implicitly guaranteeing that there are neither orphan
nor overlap indices. Optionally, the user may specify nl, in
which case the portion vl(1:nl) is used.
- nl
- In this case we are implying a generalized row-block
distribution in which each process
 gets assigned a consecutive
chunk of
gets assigned a consecutive
chunk of  global indices.
global indices.
- repl
- In this case we are asking to replicate all indices on
all processes. This is a special purpose data allocation that is
useful in the construction of some multilevel preconditioners.
- On exit from this routine the descriptor is in the build state
Notes
- On exit from this routine the descriptor is in the build
state.
- Calling the routine with
vg or parts implies that
every process will scan the entire index space to figure out the
local indices.
- Overlapped indices are possible with both
parts and
vl invocations.
- When the subroutine is invoked with
vl in
conjunction with globalcheck=.true., it will perform a scan
of the index space to search for overlap or orphan indices.
- When the subroutine is invoked with
vl in
conjunction with globalcheck=.false., no index space scan
will take place. Thus it is the responsibility of the user to make
sure that the indices specified in vl have neither orphans nor
overlaps; if this assumption fails, results will be
unpredictable.
- Orphan and overlap indices are
impossible by construction when the subroutine is invoked with
nl (alone), or vg.
Next: psb_cdins Communication
Up: Data management routines
Previous: Data management routines
Contents